Abstract
In multimodal learning, CLIP has been recognized as the de facto method for learning a shared latent space across multiple modalities, placing similar representations close to each other and moving them away from dissimilar ones. Although CLIP-based losses effectively align modalities at the semantic level, the resulting latent spaces often remain only partially shared, revealing a structural mismatch known as the modality gap. While the necessity of addressing this phenomenon remains debated, particularly given its limited impact on instance-wise tasks (e.g., retrieval), we prove that its influence is instead strongly pronounced in group-level tasks (e.g., clustering). To support this claim, we introduce a novel method designed to consistently reduce this discrepancy in two-modal settings, with a straightforward extension to the general n-modal case. Through our extensive evaluation, we demonstrate our novel insight: while reducing the gap provides only marginal or inconsistent improvements in traditional instance-wise tasks, it significantly enhances group-wise tasks. These findings may reshape our understanding of the modality gap, highlighting its key role in improving performance on tasks requiring semantic grouping.
TL;DR
1
Retrieval is rank-based. A cross-modal offset leave relative rankings almost unchanged.
2
Clustering is geometry-sensitive. Absolute placement and within-class scatter impact group-wise semantics.
3
Closing the gap aligns groups. The latent space becomes semantically shared rather than ranking-based across modalities.
Core intuition
Retrieval and clustering respond differently to the modality gap.
How and Why?
1
Retrieval depends on relative ranking, so a global offset can leave top matches mostly intact.
2
Clustering depends on the absolute geometry of the latent space, so the same offset increases within-class scatter and weakens semantic grouping.
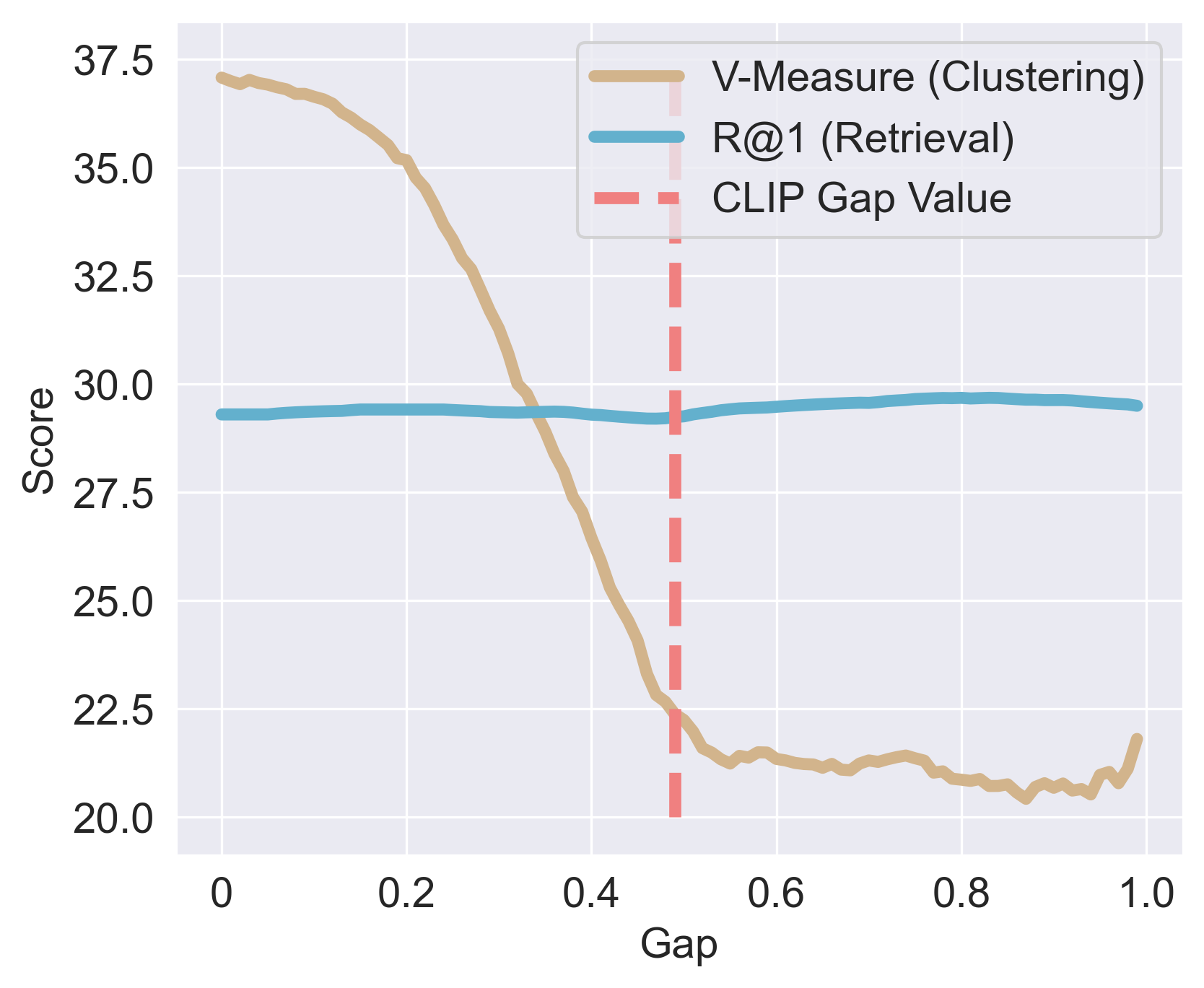
As the gap is reduced, clustering improves strongly while retrieval stays comparatively flat.
Method
The method combines an explicit alignment term for matching pairs with a centroid-level uniformity term that preserves an expressive, well-spread latent geometry. The final loss is added on top of the contrastive objective.
$$\mathcal{L}_{\text{ATP}} = \frac{1}{M-1} \sum_{m \in M, m \neq a} \left( \frac{1}{N} \sum_{i=1}^N \left( || \mathbf{z}_i^m - \mathbf{z}_i^a ||^2_2 \right) \right)$$
$$\mathcal{L}_{\text{CU}} = \log \left( \frac{1}{N} \sum_{i=1}^{N} \sum_{j=1, j\neq i}^{N} \exp \left( -2 || \boldsymbol \mu_i - \boldsymbol \mu_j ||^2_2 \right) \right)$$
$$\mathcal{L}_{\text{CLgap}} = \mathcal{L}_{\text{gap}} + \frac{1}{2} \cdot \left( \mathcal{L}^{(m \to n)} + \mathcal{L}^{(n \to m)} \right) ,\quad \text{where } \mathcal{L}_{\text{gap}} = \mathcal{L}_{\text{ATP}} + \mathcal{L}_{\text{CU}}$$
\( \mathcal{L}_{\text{ATP}} \)
Align true pairs
Pulls matching samples across modalities closer in the space.
\( \mathcal{L}_{\text{CU}} \)
Spread centroids
Prevents collapse by keeping semantic centroids uniform over the hypersphere.
Combined objective
Close the gap
Preserves pairwise alignment while improving the geometry needed for group-wise semantics.
Latent-space visualizations
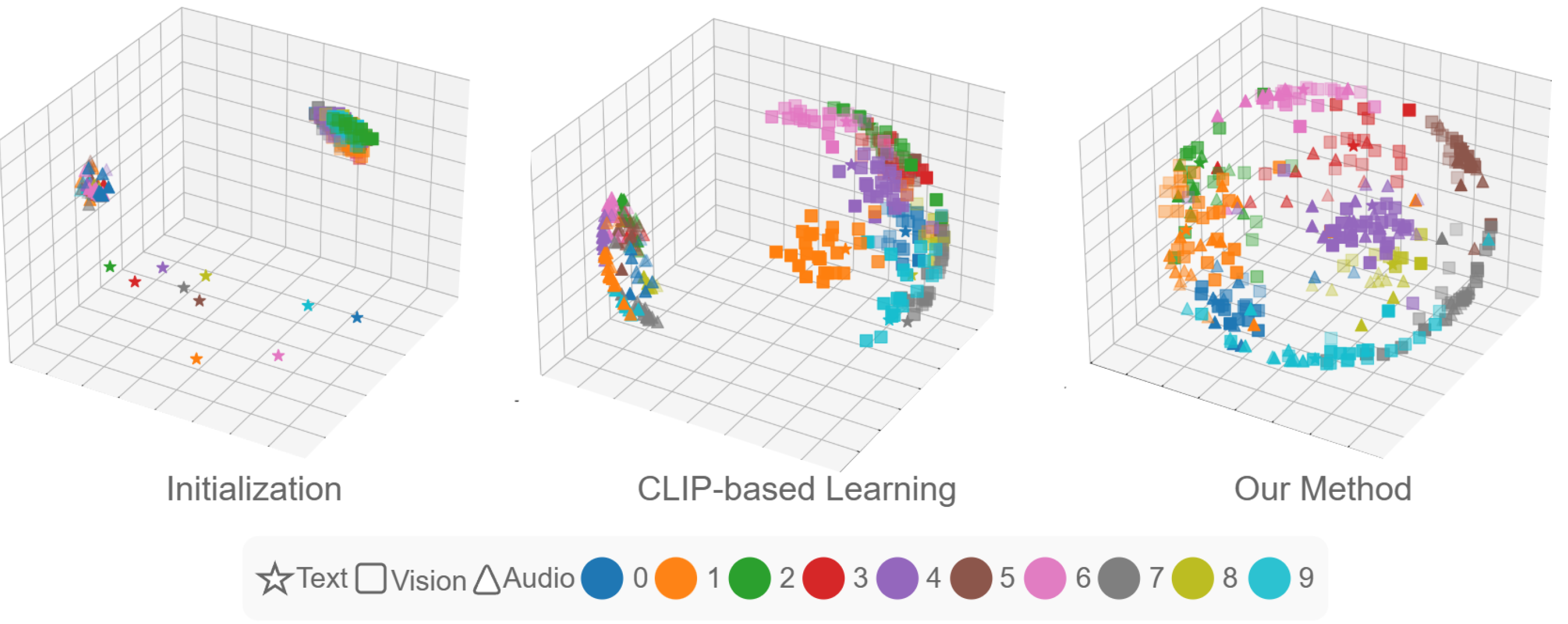
On AV-MNIST, we show the contrast between initialization, CLIP-based learning, and the proposed method. The key shift is from modality-separated clusters to class-aligned multimodal neighborhoods.
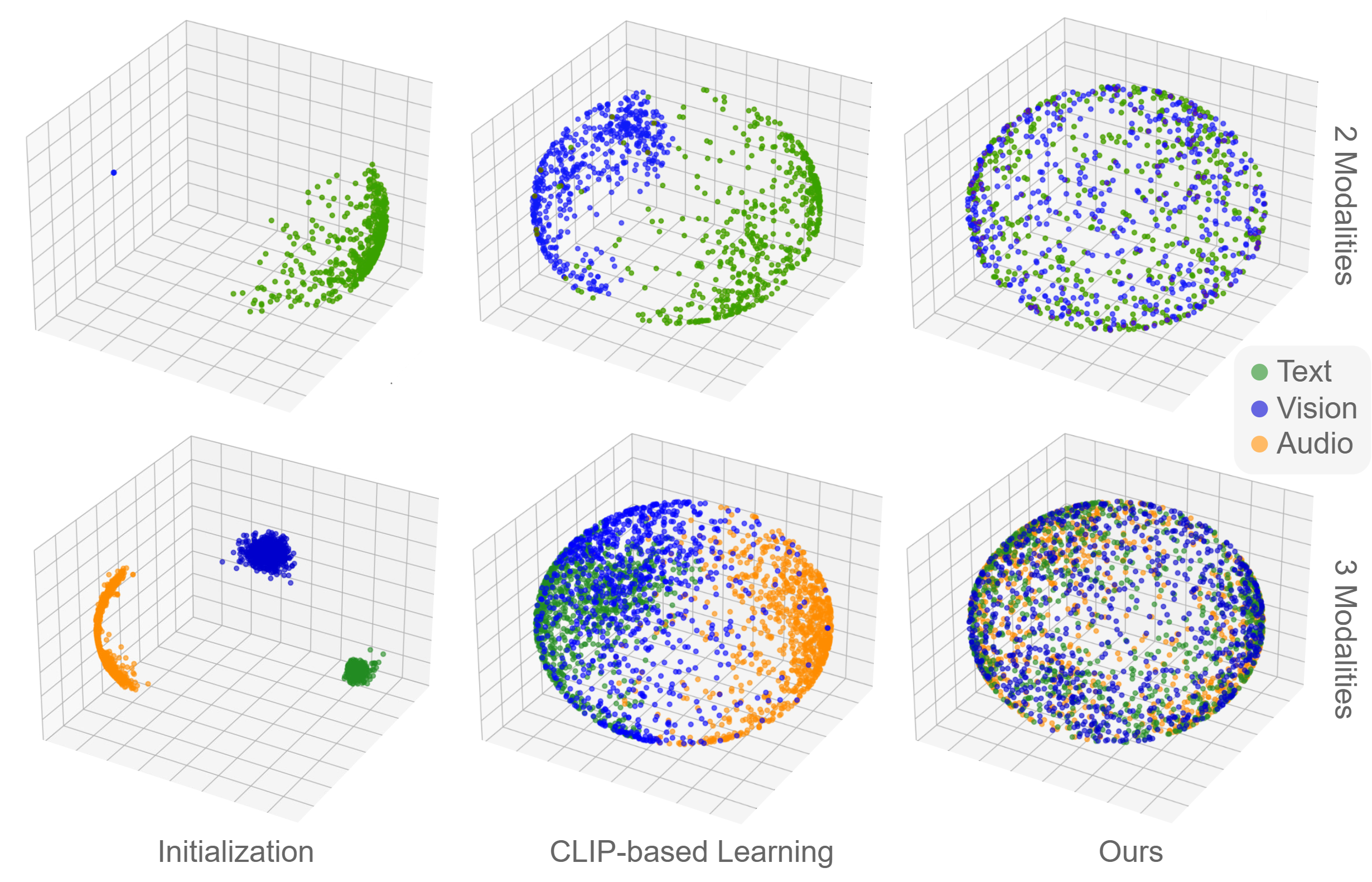
PCA visualizations. Initialization begins fragmented, CLIP preserves a visible gap, and the proposed objective produces overlapping modality distributions over the shared space.
Results
MSCOCO gap
0.47 → 0.03
Large reduction in modality separation
MSCOCO V-Measure
12.98 → 23.63
Substantial group-wise improvement
MSCOCO Cosine True Pairs
0.34 → 0.77
True pairs become much more aligned
MSR-VTT gap
0.29 → 0.07
Trimodal latent space becomes tighter
MSR-VTT V-Measure
23.3 → 32.1
Clustering clearly benefits
MSR-VTT T2A R@1
10.3 → 11.8
Retrieval shifts are smaller but preserved
| Dataset | Metric | CLIP (LT) | Ours | Notes |
|---|---|---|---|---|
| MSCOCO | Gap ↓ | 0.47 | 0.03 | Shared latent space is much more coherent. |
| MSCOCO | V-Measure ↑ | 12.98 | 23.63 | Group-wise semantics improve strongly. |
| MSR-VTT | Gap ↓ | 0.29 | 0.07 | The same effect holds in the trimodal setting. |
| MSR-VTT | V-Measure ↑ | 23.3 | 32.1 | Clustering benefits remain clear at larger scale. |
Test it in the wild
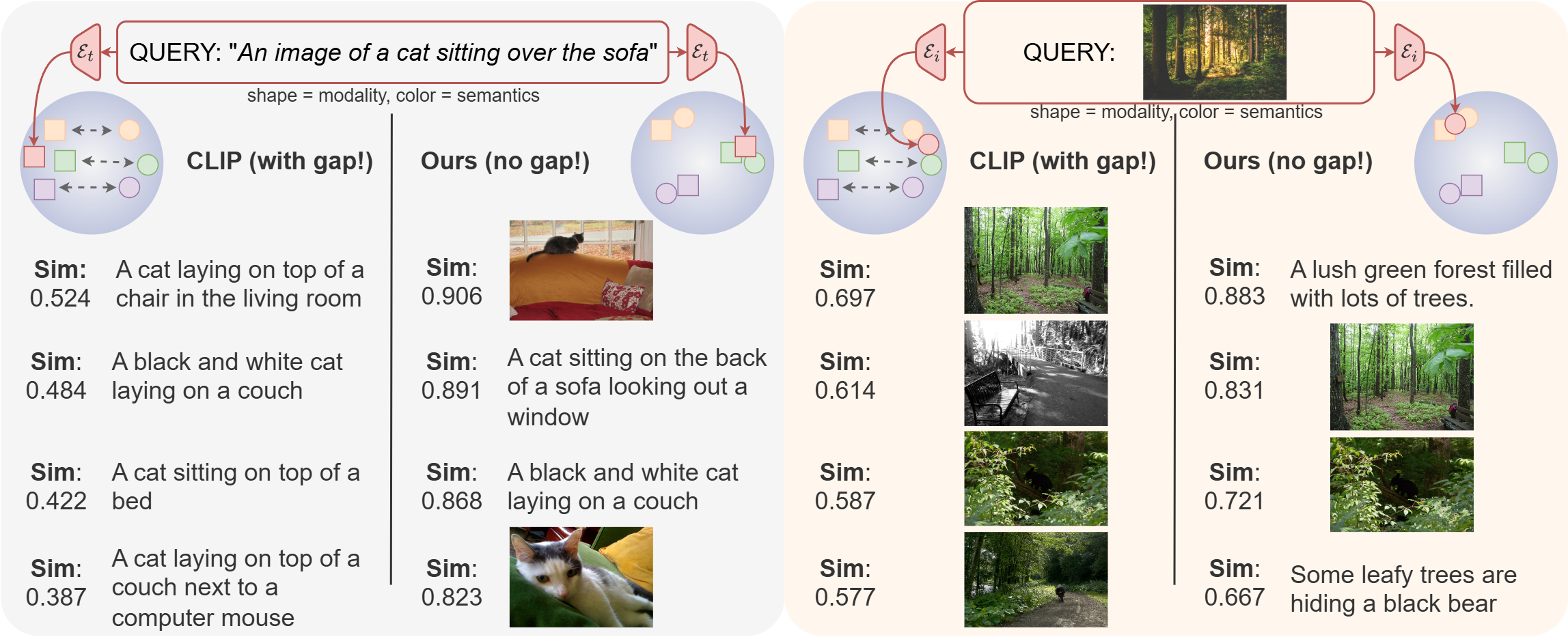
A
With gap: similarity remains entangled with modality identity.
B
Without gap: semantic neighborhoods become cross-modal rather than modality-specific.
C
Takeaway: the latent space becomes useful for grouping, browsing, and additional downstream tasks.
BibTeX
@inproceedings{grassucci2026closing,
title = {Closing the Modality Gap Aligns Group-Wise Semantics},
author = {Grassucci, Eleonora and Cicchetti, Giordano and Frasca, Emanuele and Uncini, Aurelio and Comminiello, Danilo},
booktitle = {International Conference on Learning Representations},
year = {2026}
}